Juliaは数値計算や機械学習に向いたプログラミング言語です。この記事では、入門者向けにJuliaプログラミングをご紹介します。
LinuxへJuliaをインストールするには、julialang.org からJuliaをダウンロードする。
ダウンロードしたJuliaを展開する。
$ cd /home/tsuka/Downloads
$ tar xzf julia-1.7.2-linux-x86_64.tar.gz適当な場所へ配置する。
$ cd /usr/local/bin
$ sudo mv /home/tsuka/Downloads/julia-1.7.2 .
$ sudo chown -R root:root julia-1.7.2/usr/bin にシンボリックリンクを作成する。
$ cd /usr/bin
$ sudo ln -s /usr/local/bin/julia-1.7.2/bin/julia juliaバージョンアップの際は、シンボリックリンクを再作成する。古いバージョンは削除してよいが、残しておけばシンボリックリンクの向き先を変更するだけで古いバージョンに戻すことができる。
Juliaの公式サイト(https://julialang.org/)でDownloadメニューをクリックして、Juliaのインストーラをダウンロードする。
JuliaをWindows 10にインストールする場合、ダウンロードしたインストーラをダブルクリックして実行する。
Juliaのインストーラはいたってシンプルで、インストール先のフォルダ名を聞いてくるだけである。
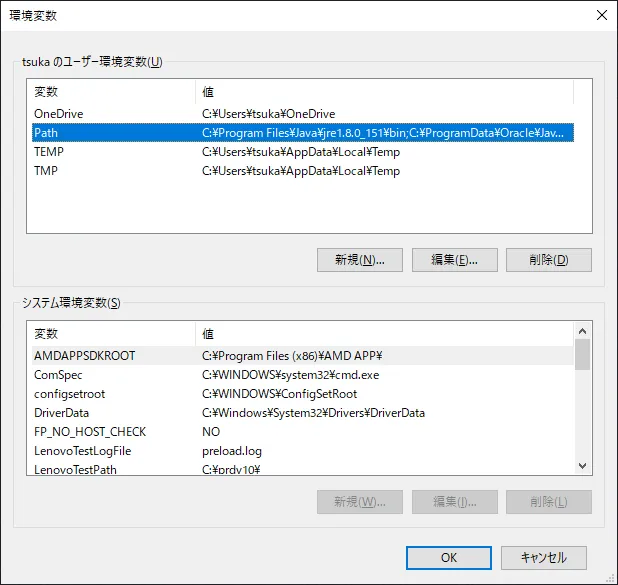
Juliaのスクリプト(*.jl)をエクスプローラでダブルクリックして起動したり、Windows PowerShellから起動するためには、Juliaの実行ファイル(julia.exe)のパスを環境変数PATHに含める必要がある。
環境変数PATHの設定は、Juliaのインストーラではやってくれないので、手動で設定する必要がある。
Windows 10で環境変数を設定するには、次の手順で操作する。
Julia を Windows にインストールした場合、以下のパスを環境変数 PATH に含める。
C:\Users\{ユーザ名}\AppData\Local\Programs\Julia-{バージョン}\bin既にインストールされているJuliaをアップデートするには、既存のJuliaをアンインストールしてから新しいバージョンのJuliaをインストールする。
Juliaのバージョンが変わるとインストール先のパスが変わるので、環境変数PATHも変更が必要になる。
Windowsの場合、スタートメニューからJuliaをクリックするとJuliaのREPLが起動する。
REPLとはRead-eval-print loopの略称で、対話型評価環境のことである。
JuliaのREPLを起動すると、バナーとコマンド入力を促すプロンプトが表示される。
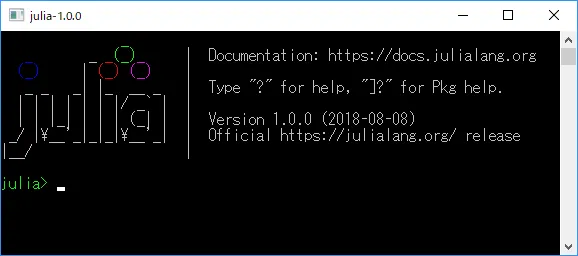
Juliaを終了させるには、Ctrl + D または exit() とタイプする。
Windows PowerShellやコマンドプロンプトからJuliaを起動するには、julia.exeを実行する。
ファイルの実行コードを非対話的に実行するには、julia.exeの引数に実行するスクリプトファイル名と引数を指定する。
C:> julia.exe script.jl arg1 arg2スクリプトの名前はグローバル定数PROGRAM_FILE、スクリプトの引数はグローバル定数ARGSで参照できる。
Juliaをアイコンから実行するか、シェルからJuliaを引数なしで実行すると、REPLが起動する。
REPL とは Read-eval-print loop の略称で、対話型評価環境のことである。
JuliaのREPLには、次に示す3つのモードがある。
JuliaのREPLを起動すると、初めはJuliaモードになっている。
REPLがJuliaモードの場合、プロンプトは次のように表示される。
julia>Juliaモードでは入力したコードが評価されて、その結果が表示される。
julia> 1 + 2
3
julia>REPLのJuliaモードで「]」を入力すると、パッケージモードに切り替わる。
REPLがパッケージモードの場合、プロンプトは次のように表示される。
(@v1.7) pkg>※表示はJuliaのバージョンによって異なる。
パッケージモードでは、Juliaにパッケージを追加できる。
たとえば、Julia に HTTP.jl パッケージを追加するには、REPLのパッケージモードで次のように入力する。
(@v1.7) pkg> add HTTP※拡張子の .jl は指定しない。
パッケージモードを終了してJuliaモードへ戻るには、Backspaceキーを押す。
REPLのJuliaモードで「?」を入力すると、ヘルプモードに切り替わる。
REPLがヘルプモードの場合、プロンプトは次のように表示される。
help?>ヘルプモードでは、入力したキーワードについてのヘルプが表示される。
help?> println
search: println printstyled print sprint isprint
println([io::IO], xs...)
Print (using print) xs followed by a newline. If io is not supplied, prints to stdout.
Examples
≡≡≡≡≡≡≡≡≡≡
julia> println("Hello, world")
Hello, world
julia> io = IOBuffer();
julia> println(io, "Hello, world")
julia> String(take!(io))
"Hello, world\n"
julia>ヘルプを表示すると、ヘルプモードを終了してJuliaモードへ戻る。
Juliaのプロンプトに計算式を入力してEnterキーを押下すると、計算結果が表示される。
julia> 1 + 2 * 3
7
julia>REPLでは記号を簡単に入力できる機能がある。たとえば、\piと入力してタブキーを押すと、πに変換される。
julia> π
π = 3.1415926535897...
julia>他にも次の文字を変換できる。
| 入力文字列 | タブキーで変換できる記号 |
|---|---|
| \Alpha | Α |
| \alpha | α |
| \beta | β |
| \gamma | γ |
| \delta | δ |
| \delta | δ |
| \epsilon | ϵ |
| \zeta | ζ |
| \eta | η |
| \theta | θ |
| \iota | ι |
| \kappa | κ |
| \lambda | λ |
| \mu | μ |
| \nu | ν |
| \pi | π |
| \rho | ρ |
| \sigma | σ |
| \tau | τ |
| \upsilon | υ |
| \phi | ϕ |
| \chi | χ |
| \psi | ψ |
| \omega | ω |
Juliaを起動する際に、次に示すコマンドオプションを指定できる。
$ julia --banner=no$ julia --color==no$ julia -h$ julia -q$ julia -v
julia version 1.6.1Julia言語には次に示す3つの標準モジュールがある。
Mainは最上位モジュールで、JuliaはMainセットを現在のモジュールとして開始する。
Coreはビルトイン(組込み)と見なされる全ての識別子を含む標準モジュールである。つまり、ライブラリではなく、Julia言語の一部である。これらの定義無しには何もできないため、全てのモジュールは暗黙的に「using Core」を含む。
Baseは基本的な機能を含む標準モジュールであり、Juliaの基礎ライブラリである。ほとんどの場合にBaseが必要なので、全てのモジュールは暗黙的に「using Base」を含む。
Juliaには次に示す算術演算子がある。
| 演算子 | 説明 |
|---|---|
| x + y | 加算 |
| x - y | 減算 |
| x * y | 乗算 |
| x / y | 除算 |
| x ÷ y | 整数除算 |
| x ^ y | 乗 |
| x % y | 剰余 |
% は割った余り(剰余)を求める演算子である。実数型(Float16、Float32およびFloat64)の場合は常に0と評価される。
function fizzbuzz(x)
if x % 15 == 0
println("FizzBuzz")
elseif x % 3 == 0
println("Fizz")
elseif x % 5 == 0
println("Buzz")
else
println(x)
end
end
for i = 1:100
fizzbuzz(i)
endJuliaには次に示すブール演算子がある。
| 演算子 | 説明 |
|---|---|
| !x | 否定 |
「x && y」の式は、x と y がどちらも true の場合にのみ true と評価される。Julia言語では、まず x を評価して、x が true の場合にのみ続けて y を評価する。もし x が false であれば y は評価しない。このように結果が明らかになった段階で評価を止めることを「短絡評価」という。
短絡評価の仕組みを利用して、条件分岐処理を行うことができる。たとえば、n の値が0以下の場合にエラーを発生させるには、&& を使って次のようにする。
n <= 0 && error("n must be positive")もし n が0以下であれば、続いてerror関数が評価(実行)される。もし n が 0より大きければ、error関数は評価されない。
上記のコードは、次のように書くこともできる。
if n <= 0
error("n must be positive")
end「x || y」の式は、x と y がどちらも false の場合にのみ false と評価される。Julia言語では、まず x を評価して、x が false の場合にのみ続けて y を評価する。もし x が true であれば y は評価しない。このように結果が明らかになった段階で評価を止めることを「短絡評価」という。
短絡評価の仕組みを利用して、条件分岐処理を行うことができる。
たとえば、n の値が0以下の場合にエラーを発生させるには、|| を使って次のようにする。
n > 0 || error("n must be positive")もし n が0以下であれば、続いてerror関数が評価(実行)される。もし n が 0より大きければ、error関数は評価されない。
上記のコードは、次のように書くこともできる。
if !(n > 0)
error("n must be positive")
endJuliaには次に示すビット演算子がある。
| 演算子 | 説明 |
|---|---|
| ~x | ビット否定 |
| x & y | 論理積 |
| x | y | 論理和 |
| x ⊻ y | 排他的論理和 |
| x >>> y | 論理右シフト |
| x >> y | 算術右シフト |
| x << y | 左シフト |
>> は右シフト演算子である。
julia> 8 >> 1
4
julia> 8 >> 2
2
julia> 8 >> 3
1<< は左シフト演算子である。
julia> 1 << 1
2
julia> 1 << 2
4
julia> 1 << 3
8Juliaには次に示す代入演算子がある。
| 演算子 | 説明 |
|---|---|
| x = y | 代入 |
| x += y | 加算代入 |
| x -= y | 減算代入 |
| x *= y | 乗算代入 |
| x /= y | 除算代入 |
| x ÷= y | 整数除算代入 |
| x %= y | 剰余代入 |
| x ^= y | 乗代入 |
| x &= y | 論理積代入 |
| x |= y | 論理和代入 |
| x ⊻= y | 排他的論理和代入 |
| x >>>= y | 論理右シフト代入 |
| x >>= y | 算術右シフト代入 |
| x <<= y | 左シフト代入 |
比較演算子とは2つの値の関係性を比較して、正しければ真(true)、間違っていれば偽(false)と評価する演算子であり、関係演算子とも呼ばれる。if文やwhile文で使われることが多い。
Juliaの比較演算子はPythonなど他のプログラミング言語と似ているが、Unicodeを使って数学の記号をそのまま使えるようにしているので、≠(ノットイコール)などが使えるのが特徴である。
| 演算子 | 説明 |
|---|---|
| x == y | 等しい |
| x != y | 等しくない |
| x ≠ y | |
| x < y | 小さい |
| x <= y | 小さいか等しい |
| x ≤ y | |
| x > y | 大きい |
| x >= y | 大きいか等しい |
| x ≥ y |
Julia言語で文字リテラルを表すには、文字を引用符で囲む。
x = 'x'
y = 'y'文字リテラルにおいて、文字をUnicodeで表すこともできる。
x = '\u78'
y = '\u79'Julia言語では正規表現を使うことができる。正規表現にはいくつかの種類があるが、Juliaで使えるのはPerlの正規表現である。
文字列リテラルの前に「r」を付けることで、その文字列が正規表現であることを表わす。
regex = r"J.*"正規表現のデータ型は「String」ではなく「Regex」である。
julia> typeof("J.*")
String
julia> typeof(r"J.*")
Regex
julia>match 関数を使うことにより、正規表現にマッチする文字列や位置を取得することができる。
m = match(r"L.*", "The Julia Programming Language")
# マッチした文字列
println(m.match)
# マッチした位置
println(m.offset)マッチした位置とは、先頭の文字を1として何番目の文字から一致するかを数値で表わしたものである。
Juliaのスクリプトにはコメントを埋め込むことができる。コメントとはスクリプトの注釈で、プログラムの実行には影響を及ぼさない。
Julia言語において「#」以降は行末までコメントとなる、これを単一行コメントという。
radius = 2 #半径Julia言語において「#=」から「=#」までの範囲もコメントとなる、これを複数行コメントといい、複数の行にわたってコメントを記述できる。
#=
円の面積
引数 半径
戻り値 面積
=#
function area(r)
r * r * π
end変数とは値に関連付けられた名前で、後で使用するために値を保存する場合に便利である。
Julia言語の変数に型宣言は不要で、変数名の大文字と小文字は区別される。
julia> x = 10
10
julia> x = "Hello World!"
Hello World!
julia>多くのプログラミング言語では、変数に使える文字をASCII/ISO 8859-1 (Latin-1)の英数字記号に限っているが、Julia言語は変数名にUnicodeを使うことができるユニークな特徴がある。そのため、変数名に日本語やさまざまな記号を使うことができる。
長さ = 5
println(長さ)
♡ = "I love you"
println(♡)Juliaにおいて、条件によって処理を分岐させるにはif分を使う。
if x > y
println("xはyより大きい")
elseif x < y
println("xはyより小さい")
else
println("xはyと等しい")
endJuliaでは三項演算子を使うことができる。
condition ? expr1 : expr2conditionがtrueの場合はexpr1が評価され、falseの場合はexpr2が評価される。
三項演算子のサンプルを示す。
println(x > y ? "xはyより大きい" : x < y ? "xはyより小さい" : "xはyと等しい")while文は条件を満たす間、処理を繰り返す制御構造である。
i = 1
# iが3以下の間は繰り返す
while i <= 3
println(i)
global i += 1
end繰り返しを途中で抜けるには、break文を使用する。
i = 1
# 問答無用で繰り返す
while true
println(i)
# iが3以上なら繰り返しを抜ける
if i >= 3
break
end
global i += 1
endあらかじめ決まった回数だけ繰り返し処理をJuliaで行うには、for文を使う。
たとえば、1から10までの数字を表示するには、次のようにする。
for i = 1:10
println(i)
endここでの1:10は範囲オブジェクトであり、1から10までの連続した数値を表している。
1から2刻みで9まで(1, 3, 5, 7, 9)繰り返す場合は、範囲オブジェクトを1:2:9とする。
for i = 1:2:9
println(i)
end数値の集合をfor文で使うには、次のようにする。
for i in [1, 3, 2]
println(i)
endJuliaのfor文で文字列の集合を使うには、∈を使う。
※数学において、a ∈ A は「aは集合Aの要素である」、「aはAに属する」を意味する。
for s ∈ ["foo","bar","baz"]
println(s)
endJulia では struct キーワードを使って、構造体を定義できる。構造体とは、複数のフィールドを持つ型である。
julia> struct Point
x::Float64
y::Float64
end
julia> function distance(p::Point)
sqrt(p.x^2 + p.y^2)
end
julia> p = Point(2, 3)
Point(2.0, 3.0)
juliq> distance(p)
3.605551275463989struct で宣言した構造体は immutable であるため、値を変更できない。
julia> struct Point
x::Float64
y::Float64
end
julia> p = Point(2, 3)
Point(2.0, 3.0)
julia> p.x = 3
ERROR: setfield!: immutable struct of type Point cannot be changedmutable struct キーワードを使って定義した構造体は、値を変更できる。
julia> mutable struct Point
x::Float64
y::Float64
end
julia> p = Point(2, 3)
Point(2.0, 3.0)
julia> p.x = 3
3Julia言語における配列のインデックス(添字)は1から始まる。
a = [1, 2, 3]
println(a[1])
println(a[2])
println(a[3])
# 配列の要素数
println(length(a))スコープ(有効範囲)がグローバルな定数を宣言するには、const 修飾子を指定する。
ただし警告は出るものの、型を変更しなければ値を変えることができる。つまり、型を変更できない変数となる。
julia> const x = 1.0
1.0
julia> const x = 2
ERROR: invalid redefinition of constant x
Stacktrace:
[1] top-level scope at REPL[3]:1
julia> const x = 2.0
WARNING: redefinition of constant x. This may fail, cause incorrect answers, or produce other errors.
2.0ローカル変数を宣言するときに、データ型を指定することができる。
local x::Int32オペレーティングシステムのクリップボードの内容を文字列で返す。
cb = clipboard()引数に指定した文字列をオペレーティングシステムのクリップボードへ送る。
clipboard("example")Julia言語では無名関数を使うことができる。
julia> f = x -> 2x + 1
#1 (generic function with 1 method)
julia> f(2)
5複数の無名関数を連結することもできる。
julia> f = x -> (y -> y + 1)(2x)
#3 (generic function with 1 method)
julia> f(2)
5Juliaでは次の定数があらかじめ定義されている。
| 定数 | 説明 |
|---|---|
| JULIA_HOME | 実行可能ファイルjuliaを含むディレクトリのフルパス |
プログラミング言語におけるプリミティブ型とは、言語の最も基本的なデータ型である。整数や文字、真偽値など、単一の単純な値を扱うための型を指す。Juliaには、以下に示すプリミティブ型がある。
| 型 | スーパータイプ | ビット数 | 説明 |
|---|---|---|---|
| Int8 | Signed | 8 | 符号あり8ビット整数型 |
| Int16 | Signed | 16 | 符号あり16ビット整数型 |
| Int32 | Signed | 32 | 符号あり32ビット整数型 |
| Int64 | Signed | 64 | 符号あり64ビット整数型 |
| Int128 | Signed | 128 | 符号あり128ビット整数型 |
| UInt8 | Unsigned | 8 | 符号なしビット整数型 |
| UInt16 | Unsigned | 16 | 符号なし16ビット整数型 |
| UInt32 | Unsigned | 32 | 符号なし32ビット整数型 |
| UInt64 | Unsigned | 64 | 符号なし64ビット整数型 |
| UInt128 | Unsigned | 128 | 符号なし128ビット整数型 |
| Float16 | AbstractFloat | 16 | 16ビット浮動小数点数 |
| Float32 | AbstractFloat | 32 | 32ビット浮動小数点数 |
| Float64 | AbstractFloat | 64 | 64ビット浮動小数点数 |
| Bool | Integer | 8 | 真偽値(trueまたはfalse) |
| Char | AbstractChar | 32 | 文字 |
抽象型はインスタンス化できない。
| 抽象型 | スーパータイプ | 説明 |
|---|---|---|
| Number | Any | 数値 |
| Real | Number | 実数 |
| AbstractFloat | Real | 浮動小数点数 |
| Integer | Real | 整数 |
| Singed | Integer | 符号あり整数 |
| Unsigned | Integer | 符号なし整数 |
JuliaLang.org contributors (2022) Julia Documentation